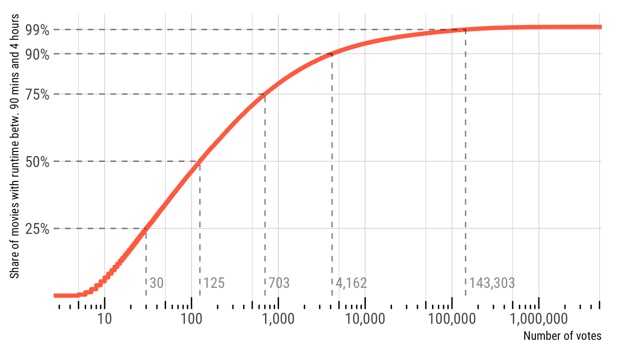
So, the Internet Movie Database (IMDb) has some nicely precompiled datasets that even seem to be updated on a daily basis. Let’s put them to good(?) use. We’ll use two files because the file with ratings only has unique identifiers that have to be merged with the actual names. I’ve downloaded these files before, so they might be a bit out of date. I am not doing this here, but it might be easy to modify the vroom() calls below to always get the up-to-date data gzipped files directly from the website.
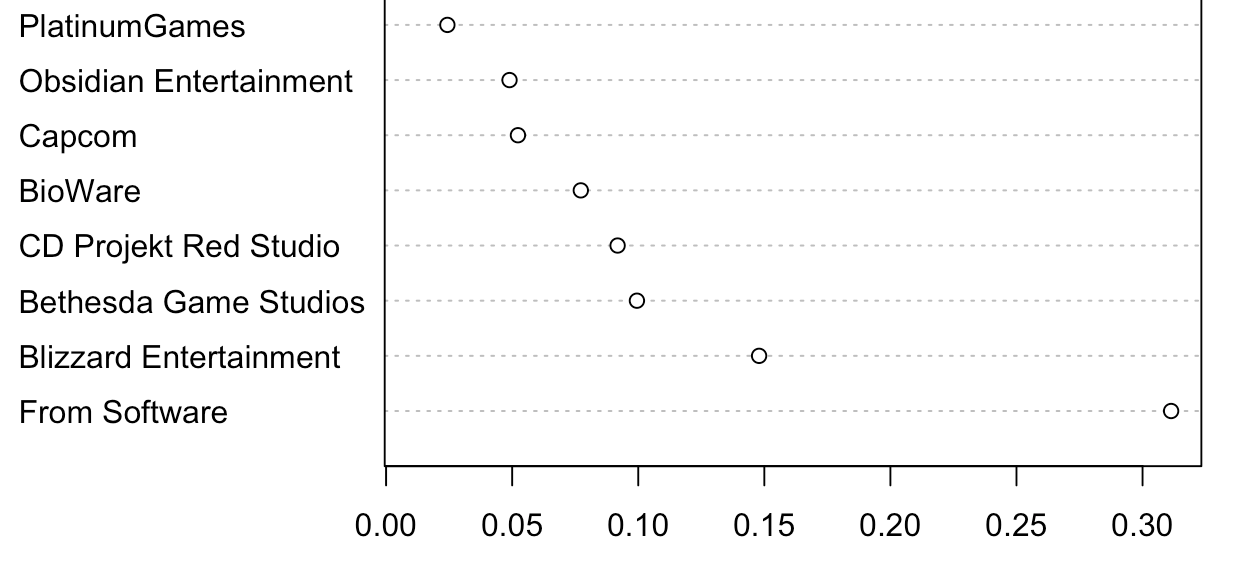
tl;dr Using a Naïve Bayesian classifier and a dataset of 1515 video game ratings, I am predicting which developer is most likely to make a game with specific properties (metascore, ESRB rating, genre, platform) in the future.
Naïve Bayesian learning A Naïve Bayes classifier is a very simple method to predict categorial outcomes. A well-known application is text classification, especially predicting whether a text is spam. Here, the classifier tries to use the information about the occurrence of certain words in telling us whether an e-mail message is spam or not.
What I will show you In this post, I want to show you a few ways how you can save your datasets in R. Maybe, this seems like a dumb question to you. But after giving quite a few R courses mainly - but not only - for R beginners, I came to acknowledge that the answer to this question is not obvious and the different possibilites can be confusing.